01 (Apache) Kafka란
1. 정의:
- a fast, scalable and fault-tolerant publish-subscribe messaging system
- a message queue system that can be used in stream processing
- Kafka quickly evolved from messaging queue to a full-fledged event streaming platform capable of handling over 1 million messages per second, or trillions of messages per day
- a distributed data store optimized for ingesting/processing streaming data in real-time
- Streaming data: data that is continuously generated by thousands of data sources, which typically send the data records in simultaneously
- as a real-time, scalable, and durable system, Kafka can be used for fault-tolerant storage as well as for other use cases (e.g., stream processing, centralized data management, metrics, log aggregation, event sourcing, etc.)
- available locally or fully-manages via Apache Kafka on Confluent Cloud
2. 주요 기능 3가지
- Publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems
- Store streams of events in the order in which records were generated,durably and reliably for as long as you want
- Process streams of events as they occur or retrospectively
- All these functionalities are provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner
- Kafka can be deployed on bare-metal hardware, virtual machines, and containers, and on-premises as well as in the cloud
- You can choose between self-managing your Kafka environments and using fully managed services offered by a variety of vendors
02 개념 정리
1. Message Queue란
- aka 'point-to-point communication'
- can have one or more consumers and/or producers
- in a message queue with multiple consumers, the queue will attempt to distribute the messages evenly across them, with the guarantee being that every message will only be delivered once
- when all consumers are busy, the queue (or "broker") will store messages, making it a durable queue
- to ensure the broker doesn't drop messages that haven't been delivered yet, the queue needs to persist
- two important qualities: durability and persistency
2. Event Streaming이란
- the digital equivalent of the human body's central nervous system
- the practice of
- capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events
- storing these event streams durably for later retrieval
- manipulating, processing, and reacting to the event streams in real-time as well as retrospectively
- routing the event streams to different destination technologies as needed
- Event streaming thus ensures a continuous flow and interpretation of data so that the right information is at the right place, at the right time
- 구체적으로,
- messages are organized into log files or topics
- one or more consumers can subscribe to a log file/topic to receive all messages that come through that stream
- with proper setup, a streaming broker will deliver the same message to every subscriber, in a specific order (→ publish-subscribe pattern)
- active subscribers will always get the message, but with this type of message broker, new subscribers can access the logs file and read messages from any point in time
3. Message Queue vs Streaming 차이
Message Queue |
Streaming |
|
| 메세지 전달 | Message queues only deliver each message once, to a single consumer | Streaming brokers can deliver the same message to many consumers without the need for replication |
| 처리 방식 | Message queues process on a first-come, first-serve basis (FIFO) | Consumers can be set up to do different things with the same message |
| 전달 순서 | Message queues may not deliver in the same order messages are queued | Streaming brokers always deliver in the same order messages are queued |
| 예 | RabbitMQ | Kafka |
4. Kafka의 주요 개념 및 용어
1) Event (= record, message)
- An event records the fact that "something happened" in the world or in your business
- When you read or write data to Kafka, you do this in the form of events
- Conceptually, an event has a key, value, timestamp, and optional metadata headers
- 예)
- Event key: "Alice"
- Event value: "Made a payment of $200 to Bob"
- Event timestamp: "Jun. 25, 2020 at 2:06 p.m."
2) Brokers
- Kafka cluster is composed of multiple servers, called brokers, which serve and receive data
- Each broker is assigned with an integer ID
- Each broker contains certain topic partitions and connecting to any broker will connect you to the entire cluster
3) Producers and Consumers
- Producers: Client applications that publish (write) events to Kafka
- Consumers: Client applications that subscribe to (read and process) these events
- In Kafka, Producers and Consumers are fully decoupled (분리되다) and agnostic of each other, which is a key design element to achieve the high scalability that Kafka is known for
- 예) Producers never need to wait for Consumers. Kafka provides guarantees such as the ability to process events exactly-once.
4) Topics
- Events are organized and durably stored in topics (DB의 table 같은 개념 - constraints는 없음)
- Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder
- any number of topics are possible as long as they have different names because a topic is identified by its name
- 예) topic name could be "payments"
- Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events
- Events in a topic can be read as often as needed—unlike traditional messaging systems, events are not deleted after consumption. Instead, you define for how long Kafka should retain your events through a per-topic configuration setting, after which old events will be discarded.
5) Partition
- Topics are split into partitions (i.e. a partition is a part of the topic)
- You can have any number of partitions per topic (having more partitions = having more parallelism)
- Each partition has guaranteed order, not across the partitions
- Each message/event w/n a partition gets an incremental id, called offset
- immutable: once the data is written to a partition, it can’t be changed
- This distributed placement of your data is very important for scalability because it allows client applications to both read and write the data from/to many brokers at the same time
- When a new event is published to a topic, it is actually appended to one of the topic's partitions
- Events with the same event key (e.g., a customer or vehicle ID) are written to the same partition, and Kafka guarantees that any consumer of a given topic-partition will always read that partition's events in exactly the same order as they were written
- 3
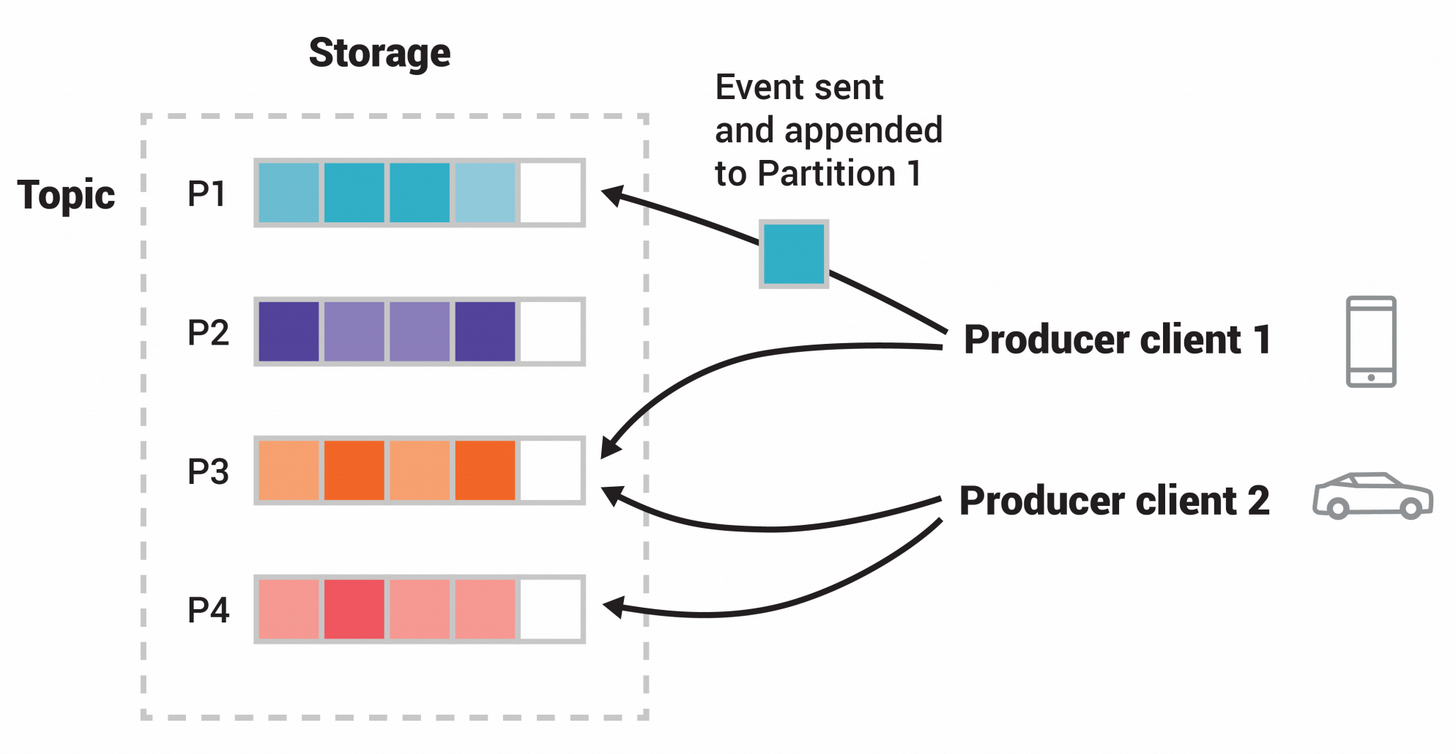
Figure: This example topic has four partitions P1–P4. Two different producer clients are publishing, independently from each other, new events to the topic by writing events over the network to the topic's partitions. Events with the same key (denoted by their color in the figure) are written to the same partition. Note that both producers can write to the same partition if appropriate. 
6) Replicate
- To make your data fault-tolerant and highly-available, every topic can be replicated, even across geo-regions or datacenters, so that there are always multiple brokers that have a copy of the data just in case things go wrong, you want to do maintenance on the brokers, and so on
- A common production setting is a replication factor of 3 (i.e., there will always be 3 copies of your data)
- This replication is performed at the level of topic-partitions
03 Kafka의 사용
- Kafka is commonly used to build real-time streaming data pipelines and real-time streaming applications
- It combines messaging, storage, and stream processing to allow storage and analysis of both historical and real-time data
- A data pipeline reliably processes and moves data from one system to another, and a streaming application is an application that consumes streams of data
- For example, if you want to create a data pipeline that takes in user activity data to track how people use your website in real-time, Kafka would be used to ingest and store streaming data while serving reads for the applications powering the data pipeline
- Kafka is also often used as a message broker solution, which is a platform that processes and mediates communication between two applications
1. Messaging
- Kafka works well as a replacement for a more traditional message broker.
- Message brokers are used for a variety of reasons (to decouple 분리 processing from data producers, to buffer unprocessed messages, etc).
- In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
- In our experience messaging uses are often comparatively low-throughput, but may require low end-to-end latency and often depend on the strong durability guarantees Kafka provides.
- In this domain Kafka is comparable to traditional messaging systems such as ActiveMQ or RabbitMQ.
2. Website Activity Tracking
- The original use case for Kafka was to be able to rebuild a user activity tracking pipeline as a set of real-time publish-subscribe feeds
- This means site activity (page views, searches, or other actions users may take) is published to central topics with one topic per activity type
- These feeds are available for subscription for a range of use cases including real-time processing, real-time monitoring, and loading into Hadoop or offline data warehousing systems for offline processing and reporting
- Activity tracking is often very high volume as many activity messages are generated for each user page view.
3. Metrics
- Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
4. Log Aggregation
- Many people use Kafka as a replacement for a log aggregation solution. Log aggregation typically collects physical log files off servers and puts them in a central place (a file server or HDFS perhaps) for processing
- Kafka abstracts away the details of files and gives a cleaner abstraction of log or event data as a stream of messages
- This allows for lower-latency processing and easier support for multiple data sources and distributed data consumption
- In comparison to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger durability guarantees due to replication, and much lower end-to-end latency.
5. Stream Processing
- Many users of Kafka process data in processing pipelines consisting of multiple stages, where raw input data is consumed from Kafka topics and then aggregated, enriched, or otherwise transformed into new topics for further consumption or follow-up processing.
- For example, a processing pipeline for recommending news articles might crawl article content from RSS feeds and publish it to an "articles" topic; further processing might normalize or deduplicate this content and publish the cleansed article content to a new topic; a final processing stage might attempt to recommend this content to users.
- Such processing pipelines create graphs of real-time data flows based on the individual topics.
- Starting in 0.10.0.0, a light-weight but powerful stream processing library called Kafka Streams is available in Apache Kafka to perform such data processing as described above.
- Apart from Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
6. Event Sourcing
- Event sourcing is a style of application design where state changes are logged as a time-ordered sequence of records. Kafka's support for very large stored log data makes it an excellent backend for an application built in this style.
7. Commit Log
- Kafka can serve as a kind of external commit-log for a distributed system.
- The log helps replicate data between nodes and acts as a re-syncing mechanism for failed nodes to restore their data.
- The log compaction feature in Kafka helps support this usage.
- In this usage Kafka is similar to Apache BookKeeper project.
04 Kafka의 작동 원리
1. In a Nutshell
- Kafka is a distributed system consisting of Servers and Clients that communicate via a high-performance TCP network protocol
- It can be deployed on bare-metal hardware, virtual machines, and containers in on-premise as well as cloud environments
1) Servers
- Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud regions
- Some of these servers form the storage layer, called the brokers
- Other servers run Kafka Connect to continuously import and export data as event streams to integrate Kafka with your existing systems such as relational DBs as well as other Kafka clusters
- To let you implement mission-critical use cases, a Kafka cluster is highly scalable and fault-tolerant: if any of its servers fails, the other servers will take over their work to ensure continuous operations without any data loss
2) Clients
- Clients allow you to write distributed applications and microservices that read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner even in the case of network problems or machine failures
- Kafka ships with some such clients included, which are augmented by dozens of clients provided by the Kafka community: clients are available for Java and Scala including the higher-level Kafka Streams library, for Go, Python, C/C++, and many other programming languages as well as REST APIs
2. Queuing and Publish-Subscribing Models
- Kafka combines two messaging models, queuing and publish-subscribe, to provide the key benefits of each to consumers
- Queuing allows for data processing to be distributed across many consumer instances, making it highly scalable. However, traditional queues aren’t multi-subscriber
- The publish-subscribe approach is multi-subscriber, but because every message goes to every subscriber it cannot be used to distribute work across multiple worker processes
- Kafka uses a partitioned log model to stitch together these two solutions. A log is an ordered sequence of records, and these logs are broken up into segments, or partitions, that correspond to different subscribers. This means that there can be multiple subscribers to the same topic and each is assigned a partition to allow for higher scalability
- Finally, Kafka’s model provides replayability, which allows multiple independent applications reading from data streams to work independently at their own rate
1) Queuing

2) Publish-Subscribe

05 Kafka의 장점
| 장점 | 설명 |
| 확장성 Scalability |
Kafka’s partitioned log model allows data (partitions) to be distributed across multiple servers, making it scalable beyond what would fit on a single server |
| 빠른 속도 Fast |
Kafka decouples (분) data streams so there is very low latency, making it extremely fast |
| 내구성 Durable |
Partitions are distributed and replicated across many servers, and the data is all written to disk. This helps protect against server failure, making the data very fault-tolerant and durable |
06 다양한 모델을 통합하는 Kafka의 아키텍처 (구조)
- Kafka combines two different messaging models (i.e., messaging queue & publish-subscribe approach) by publishing records to different topics:
- Each topic has a partitioned log, which is a structured commit log that keeps track of all records in order and appends new ones in real time. These partitions are distributed and replicated across multiple servers, allowing for high scalability, fault-tolerance, and parallelism.
- Each consumer is assigned a partition in the topic, which allows for multi-subscribers while maintaining the order of the data.
- Kafka also acts as a very scalable and fault-tolerant storage system by writing and replicating all data to disk.
- By default, Kafka keeps data stored on disk until it runs out of space, but the user can also set a retention limit.
- Kafka Architecture
- Kafka cluster provides high-throughput stream event processing
- key components:
- Kafka Broker: Kafka server that allows producers to stream data to consumers. Contains topics and their respective partitions
- topic: data storage that groups similar data in a Kafka broker (테이블 하나 개)
- partition: smaller data storage w/n a topic that consumers subscribe to
- ZooKeeper: special software that manages the Kafka clusters and partitions to provide fault-tolerant streaming.
- Producers in Kafka assign a message key for each message.
- Then, the Kafka broker stores the message in the leading partition of that specific topic.
07 Kafka API
| API 종류 | 설명 |
| Producer API | allows applications to publish (write/send) streams of data (events) to topics in the Kafka cluster |
| Consumer API | allows applications to subscribe (read) streams of data (events) from topics in the Kafka cluster |
| Streams API | allows transforming streams of data from input topics to output topics |
| Connect API | allows implementing connectors that continually pull from some source system or application into Kafka or push from Kafka into some sink system or application |
| Admin API | allows managing and inspecting topics, brokers, and other Kafka objects |
참조
- https://www.confluent.io/what-is-apache-kafka/
- https://developer.confluent.io/
- https://www.youtube.com/watch?v=06iRM1Ghr1k
- https://blog.iron.io/message-queue-vs-streaming/#1
- https://docs.confluent.io/kafka/overview.html
- https://kafka.apache.org/documentation/
- https://medium.com/@navdeepsharma/kafka-core-concepts-not-a-story-717728efc946